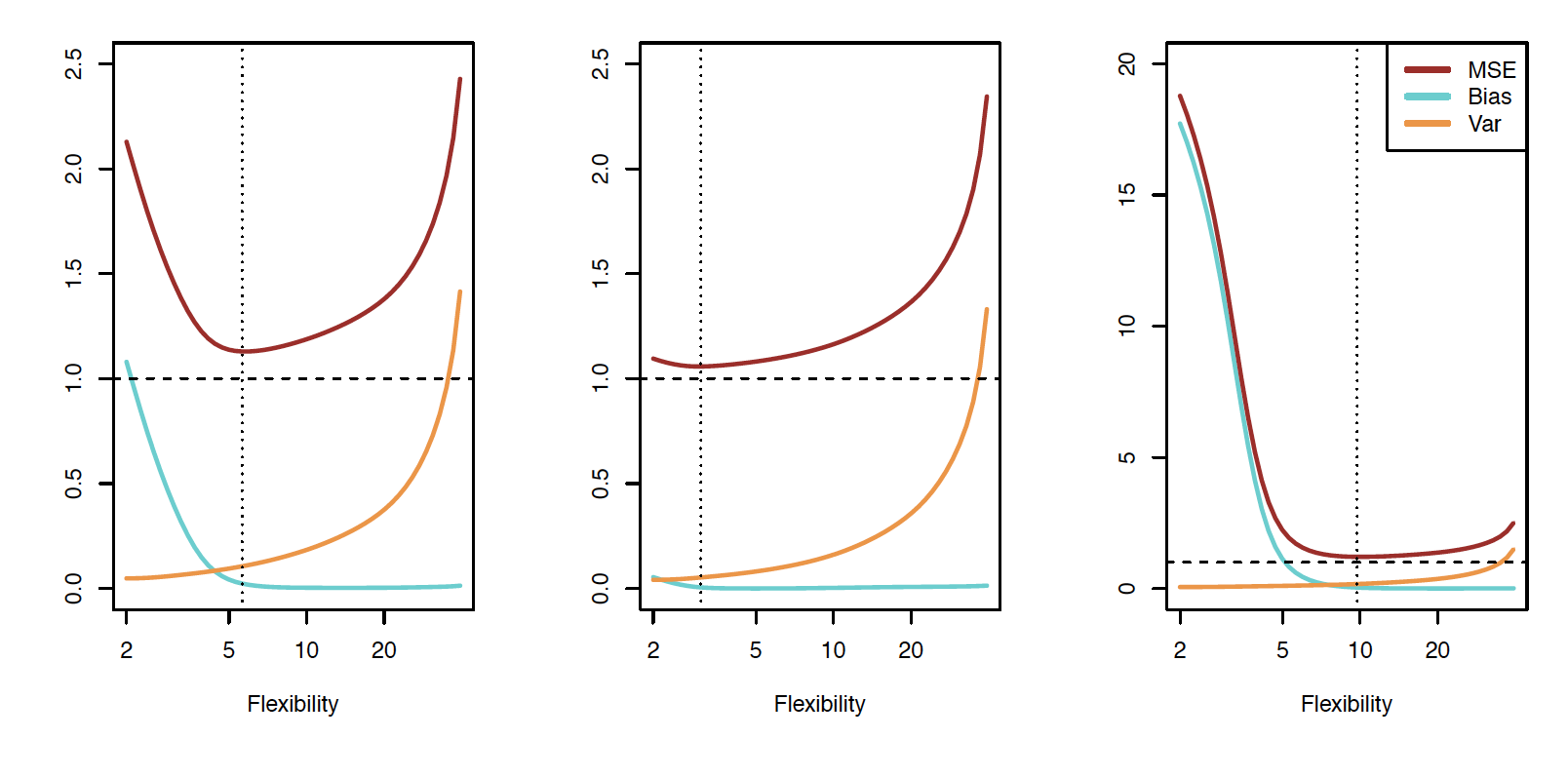
class: center, middle, inverse, title-slide # Trade-offs: Accuracy and interpretability, bias and variance ### Dr. D’Agostino McGowan --- layout: true <div class="my-footer"> <span> Dr. Lucy D'Agostino McGowan <i>adapted from slides by Hastie & Tibshirani</i> </span> </div> --- ## Regression and Classification * Regression: quantitative response * Classification: qualitative (categorical) response --- ## Regression and Classification .question[ What would be an example of a **regression** problem? ] * Regression: quantitative response * Classification: qualitative (categorical) response --- ## Regression and Classification .question[ What would be an example of a **classification** problem? ] * Regression: quantitative response * Classification: qualitative (categorical) response --- class: center, middle # Regression --- ## Auto data 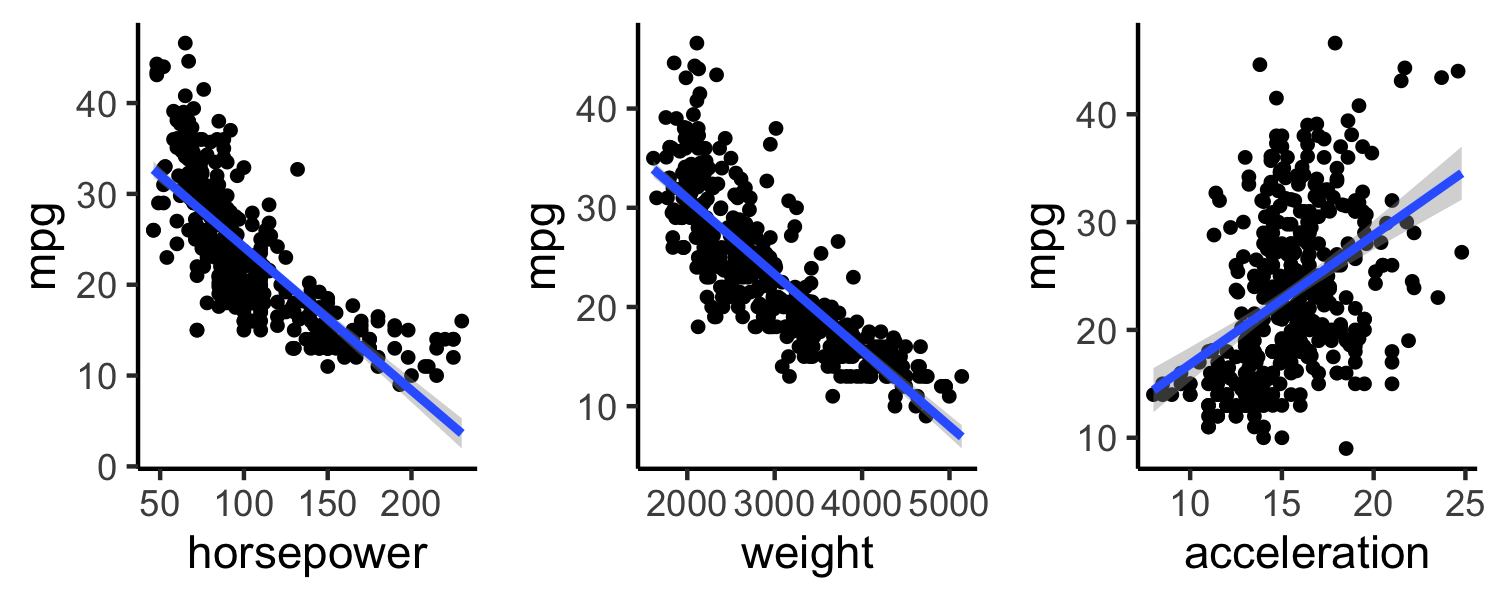<!-- --> Above are `mpg` vs `horsepower`, `weight`, and `acceleration`, with a blue linear-regression line fit separately to each. Can we predict `mpg` using these three? -- Maybe we can do better using a model: `\(\texttt{mpg} \approx f(\texttt{horsepower}, \texttt{weight}, \texttt{acceleration})\)` --- ## Notation * `mpg` is the **response** variable, the **outcome** variable, we refer to this as `\(Y\)` * `horsepower` is a **feature**, **input**, **predictor**, we refer to this as `\(X_1\)` * `weight` is `\(X_2\)` * `acceleration` is `\(X_3\)` -- * Our **input vector** is `$$X = \begin{bmatrix} X_1 \\X_2 \\X_3\end{bmatrix}$$` -- * Our **model** is `$$Y = f(X) + \epsilon$$` * `\(\epsilon\)` is our error --- ## Why do we care about `\(f(X)\)`? * We can use `\(f(X)\)` to make predictions of `\(Y\)` for new values of `\(X = x\)` -- * We can gain a better understanding of which components of `\(X = (X_1, X_2, \dots, X_p)\)` are important for explaining `\(Y\)` -- * Depending on how complex `\(f\)` is, maybe we can understand how each component ( `\(X_j\)` ) of `\(X\)` affects `\(Y\)` --- 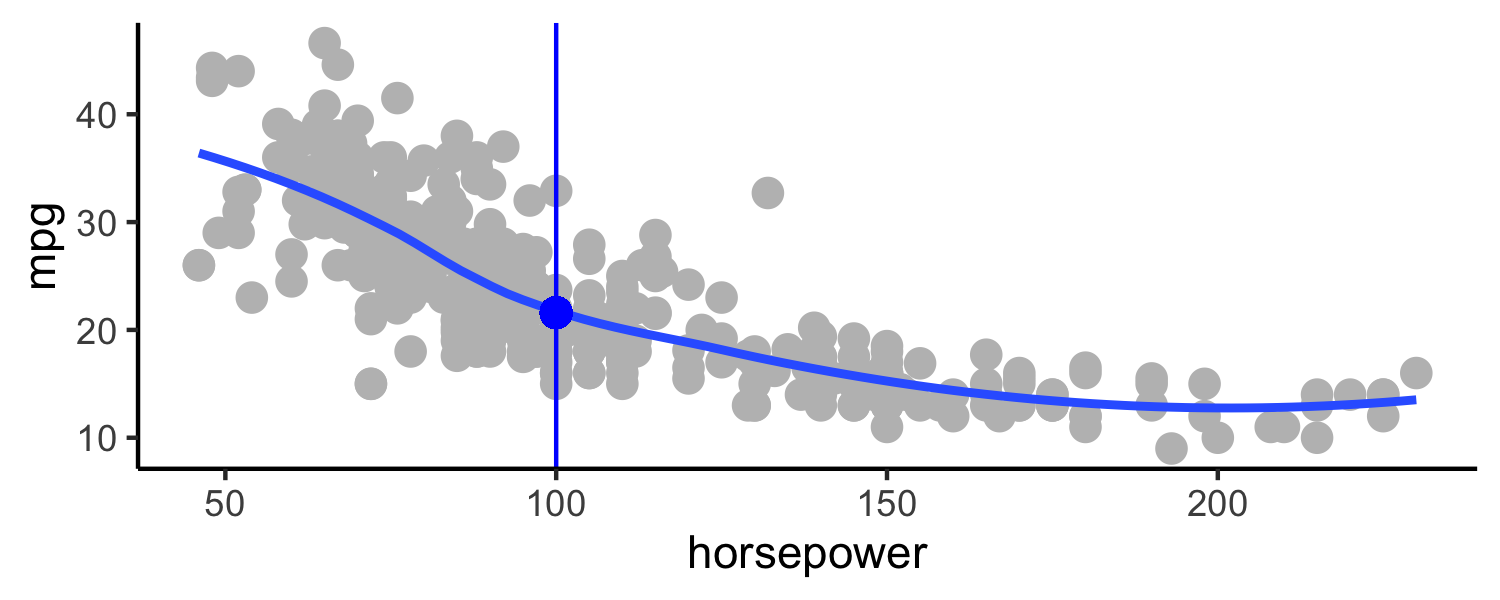<!-- --> How do we choose `\(f(X)\)`? What is a good value for `\(f(X)\)` at any selected value of `\(X\)`, say `\(X = 100\)`? There can be many `\(Y\)` values at `\(X = 100\)`. -- A good value is `$$f(100) = E(Y|X = 100)$$` -- `\(E(Y|X = 100)\)` means **expected value** (average) of `\(Y\)` given `\(X = 100\)` -- This ideal `\(f(x) = E(Y | X = x)\)` is called the **regression function** --- ## Regression function, `\(f(X)\)` * Also works or a vector, `\(X\)`, for example, `$$f(x) = f(x_1, x_2, x_3) = E[Y | X_1 = x_1, X_2 = x_2, X_3 = x_3]$$` * This is the **optimal** predictor of `\(Y\)` in terms of **mean-squared prediction error** -- .definition[ `\(f(x) = E(Y|X = x)\)` is the function that **minimizes** `\(E[(Y - g(X))^2 |X = x]\)` over all functions `\(g\)` at all points `\(X = x\)` ] -- * `\(\epsilon = Y - f(x)\)` is the **irreducible error** * even if we knew `\(f(x)\)`, we would still make errors in prediction, since at each `\(X = x\)` there is typically a distribution of possible `\(Y\)` values --- 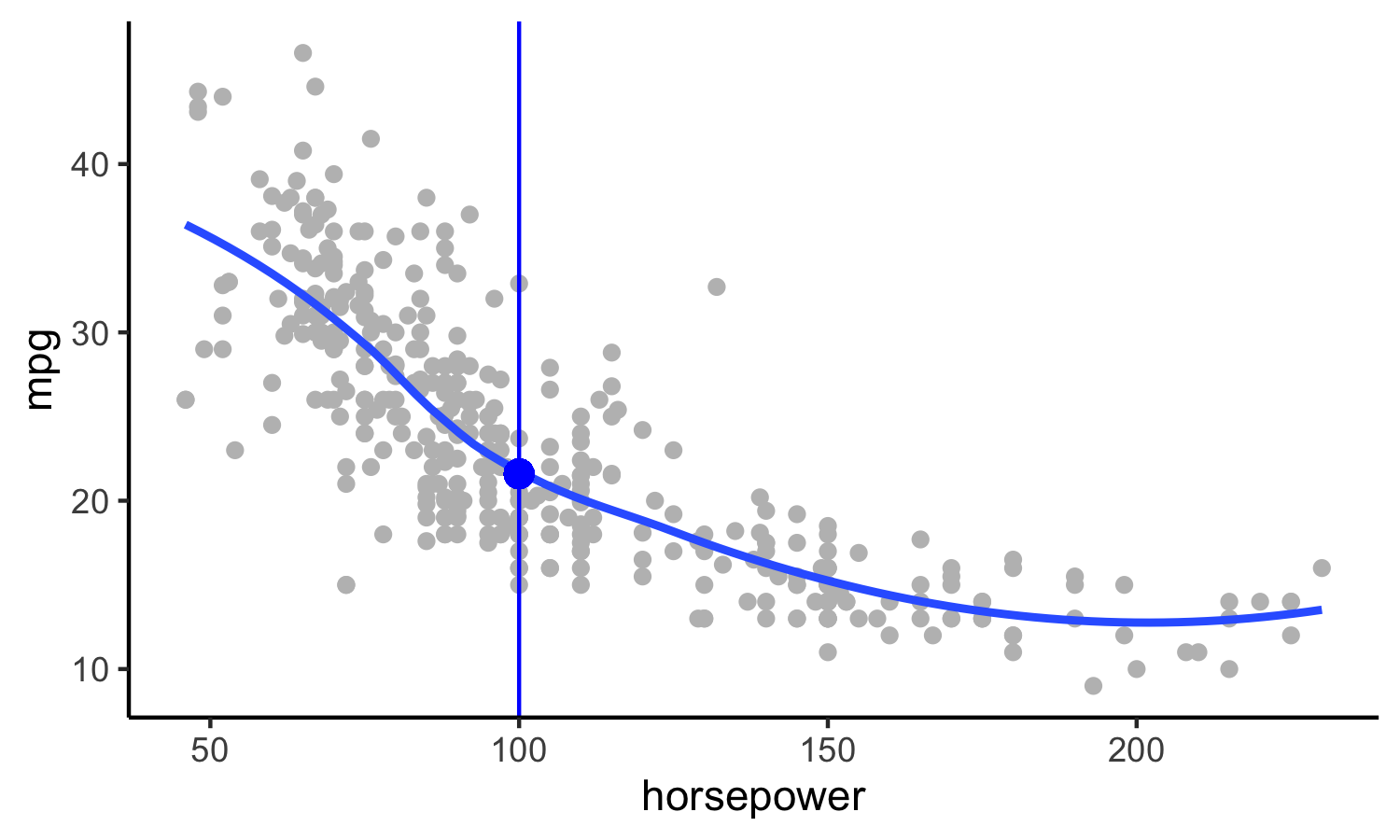<!-- --> --- <!-- --> .question[ Using these points, how would I calculate the **regression function**? ] -- * Take the average! `\(f(100) = E[\texttt{mpg}|\texttt{horsepower} = 100] = 19.6\)` --- <!-- --> .question[ This point has a `\(Y\)` value of 32.9. What is `\(\epsilon\)`? ] -- * `\(\epsilon = Y - f(X) = 32.9 - 19.6 = \color{red}{13.3}\)` --- ## The error For any estimate, `\(\hat{f}(x)\)`, of `\(f(x)\)`, we have `$$E[(Y - \hat{f}(x))^2 | X = x] = \underbrace{[f(x) - \hat{f}(x)]^2}_{\textrm{reducible error}} + \underbrace{Var(\epsilon)}_{\textrm{irreducible error}}$$` ??? * Assume for a moment that both `\(\hat{f}\)` and X are fixed. * `\(E(Y − \hat{Y})^2\)` represents the average, or expected value, of the squared difference between the predicted and actual value of Y, and Var( `\(\epsilon\)` ) represents the variance associated with the error term * The focus of this class is on techniques for estimating f with the aim of minimizing the reducible error. * the irreducible error will always provide an upper bound on the accuracy of our prediction for Y * This bound is almost always unknown in practice --- ## Estimating `\(f\)` * Typically we have very few (if any!) data points at `\(X=x\)` exactly, so we cannot compute `\(E[Y|X=x]\)` -- * For example, what if we were interested in estimating miles per gallon when horsepower was 104. <!-- --> -- 💡 We can _relax_ the definition and let `$$\hat{f}(x) = E[Y | X\in \mathcal{N}(x)]$$` --- ## Estimating `\(f\)` * Typically we have very few (if any!) data points at `\(X=x\)` exactly, so we cannot compute `\(E[Y|X=x]\)` * For example, what if we were interested in estimating miles per gallon when horsepower was 104. <!-- --> 💡 We can _relax_ the definition and let `$$\hat{f}(x) = E[Y | X\in \mathcal{N}(x)]$$` * Where `\(\mathcal{N}(x)\)` is some **neighborhood** of `\(x\)` --- ## Notation pause! <br><br><br> `$$\hat{f}(x) = \underbrace{E}_{\textrm{The expectation}}[\underbrace{Y}_{\textrm{of Y}} \underbrace{|}_{\textrm{given}} \underbrace{X\in \mathcal{N}(x)}_{\textrm{X is in the neighborhood of x}}]$$` -- .alert[ If you need a notation pause at any point during this class, please let me know! ] --- ## Estimating `\(f\)` 💡 We can _relax_ the definition and let `$$\hat{f}(x) = E[Y | X\in \mathcal{N}(x)]$$` -- * Nearest neighbor averaging does pretty well with small `\(p\)` ( `\(p\leq 4\)` ) and large `\(n\)` -- * Nearest neighbor is _not great_ when `\(p\)` is large because of the **curse of dimensionality** (because nearest neighbors tend to be far away in high dimensions) -- .question[ What do I mean by `\(p\)`? What do I mean by `\(n\)`? ] --- ## Parametric models A common parametric model is a **linear** model `$$f(X) = \beta_0 + \beta_1X_1 + \beta_2X_2 + \dots + \beta_pX_p$$` -- * A linear model has `\(p + 1\)` parameters ( `\(\beta_0,\dots,\beta_p\)` ) -- * We estimate these parameters by **fitting** a model to **training** data -- * Although this model is _almost never correct_ it can often be a good interpretable approximation to the unknown true function, `\(f(X)\)` --- class: center, middle ## Let's look at a simulated example --- <center> <img src = "img/03/sim1.png" height = "400"> </img> </center> * The <font color = "red"> red </font> points are simulated values for `income` from the model: `$$\texttt{income} = f(\texttt{education, senority}) + \epsilon$$` * `\(f\)` is the <font color = "blue"> blue </font> surface --- <center> <img src = "img/03/sim2.png" height = "400"> </img> </center> Linear regression model fit to the simulated data `$$\hat{f}_L(\texttt{education, senority}) = \hat{\beta}_0 + \hat{\beta}_1\texttt{education}+\hat{\beta}_2\texttt{senority}$$` --- <center> <img src = "img/03/sim3.png" height = "400"> </img> </center> * More flexible regression model `\(\hat{f}_S(\texttt{education, seniority})\)` fit to the simulated data * Here we use a technique called a **thin-plate spline** to fit a flexible surface --- <center> <img src = "img/03/sim4.png" height = "400"> </img> </center> And even **MORE flexible** 😱 model `\(\hat{f}(\texttt{education, seniority})\)` * Here we've basically drawn the surface to hit every point, minimizing the error, but completely **overfitting** --- ## 🤹 Finding balance * **Prediction accuracy** versus **interpretability** * Linear models are easy to interpret, thin-plate splines are not -- * Good fit versus **overfit** or **underfit** * How do we know when the fit is just right? -- * **Parsimony** versus **black-box** * We often prefer a simpler model involving fewer variables over a black-box predictor involving them all ---  --- ## Accuracy * We've fit a model `\(\hat{f}(x)\)` to some training data `\(\texttt{train} = \{x_i, y_i\}^N_1\)` * We can measure **accuracy** as the average squared prediction error over that `train` data `$$MSE_{\texttt{train}} = \textrm{Ave}_{i\in\texttt{train}}[y_i-\hat{f}(x_i)]^2$$` -- .question[ What can go wrong here? ] -- * This may be biased towards **overfit** models --- ## Accuracy <!-- --> .question[ I have some `train` data, plotted above. What `\(\hat{f}(x)\)` would minimize the `\(MSE_{\texttt{train}}\)`? ] `$$MSE_{\texttt{train}} = \textrm{Ave}_{i\in\texttt{train}}[y_i-\hat{f}(x_i)]^2$$` --- ## Accuracy <!-- --> .question[ I have some `train` data, plotted above. What `\(\hat{f}(x)\)` would minimize the `\(MSE_{\texttt{train}}\)`? ] `$$MSE_{\texttt{train}} = \textrm{Ave}_{i\in\texttt{train}}[y_i-\hat{f}(x_i)]^2$$` --- ## Accuracy <!-- --> .question[ What is wrong with this? ] -- It's **overfit!** --- ## Accuracy <!-- --> If we get a new sample, that overfit model is probably going to be terrible! --- ## Accuracy * We've fit a model `\(\hat{f}(x)\)` to some training data `\(\texttt{train} = \{x_i, y_i\}^N_1\)` * Instead of measuring **accuracy** as the average squared prediction error over that `train` data, we can compute it using fresh `test` data `\(\texttt{test} = \{x_i,y_i\}^M_1\)` `$$MSE_{\texttt{test}} = \textrm{Ave}_{i\in\texttt{test}}[y_i-\hat{f}(x_i)]^2$$` ---  Black curve is the "truth" on the left. <font color="red"> Red </font> curve on right is `\(MSE_{\texttt{test}}\)`, <font color="grey">grey </font>curve is `\(MSE_{\texttt{train}}\)`. <font color="orange">Orange</font>, <font color="blue">blue </font>and <font color="green">green </font>curves/squares correspond to fis of different flexibility. ---  Here the truth is smoother, so the smoother fit and linear model do really well ---  Here the truth is wiggly and the noise is low, so the more flexible fits do the best --- ## Bias-variance trade-off * We've fit a model, `\(\hat{f}(x)\)`, to some training data -- * Let's pull a test observation from this population ( `\(x_0, y_0\)` ) -- * The _true_ model is `\(Y = f(x) + \epsilon\)` -- * `\(f(x) = E[Y|X=x]\)` `$$E(y_0 - \hat{f}(x_0))^2 = \textrm{Var}(\hat{f}(x_0)) + [\textrm{Bias}(\hat{f}(x_0))]^2 + \textrm{Var}(\epsilon)$$` -- The expectation averages over the variability of `\(y_0\)` as well as the variability of the training data. `\(\textrm{Bias}(\hat{f}(x_0)) =E[\hat{f}(x_0)]-f(x_0)\)` * As **flexibility** of `\(\hat{f}\)` `\(\uparrow\)`, its variance `\(\uparrow\)` and its bias `\(\downarrow\)` -- * choosing the flexibility based on average test error amounts to a **bias-variance trade-off** ??? * That U-shape we see for the test MSE curves is due to this bias-variance trade-off * The expected test MSE for a given `\(x_0\)` can be decomposed into three components: the **variance** of `\(\hat{f}(x_o)\)`, the squared **bias** of `\(\hat{f}(x_o)\)` and t4he variance of the error term `\(\epsilon\)` * Here the notation `\(E[y_0 − \hat{f}(x_0)]^2\)` defines the expected test MSE, and refers to the average test MSE that we would obtain if we repeatedly estimated `\(f\)` using a large number of training sets, and tested each at `\(x_0\)` * The overall expected test MSE can be computed by averaging `\(E[y_0 − \hat{f}(x_0)]^2\)` over all possible values of `\(x_0\)` in the test set. * SO we want to minimize the expected test error, so to do that we need to pick a statistical learning method to simultenously acheive low bias and low variance. * Since both of these quantities are non-negative, the expected test MSE can never fall below Var( `\(\epsilon\)` ) --- ## Bias-variance trade-off